Quick Starts
Spring Boot Quickstart.
Lambda-style Quickstart.
About
Serverless on Your Cluster:
-
Define Endpoints in Swagger
-
Write Functions in Java, Scala, Clojure, Python, or JavaScript
-
Deploy to Mesos, Kubernets, or Swarm
-
Autoscale
Funcatron let’s you deploy serverless on any cloud provider or in your private cloud. Focus on the functions, avoid vendor lock-in.
This document sets out the goals for the Funcatron project.
Getting Started w/Spring Boot
If you’ve already got a Spring Boot app and you want to run it in Funcatron… you’re in luck. Add a few dependencies and 2 classes to your existing Spring Boot app and you’re good to go. The Spring Boot Quickstart gets you started… quickly.
And check out the Architecture Strategy for a deeper dive into Funcatron.
Getting Started Lambda-style
“Lambdas” are small units of computing… Funcations. Funcatron supports writing small funcations, associating them with REST endpoints, and autoscaling. The Developer Intro to Funcatron walks you through building Funcatron bundles Lambda-style.
And check out the Architecture Strategy for a deeper dive into Funcatron.
What’s Funcatron
Amazon’s Lambda popularized “serverless” code deployment. It’s dead simple: associate a “function” with an event. Each time the event happens, the function is applied and the function’s return value is returned to the event source. An event could be an HTTP(S) request, something on an event queue, whatever.
Functions are ephemeral. They exist for the duration of the function call. Once the function returns a value, all of its state and scope and everything else about it is assumed to go away.
Scaling this kind of architecture is simple: the more frequently a function gets applied, the more compute resources are allocated to support the function… and Bob’s Your Uncle.
The current popular function runners (competitors to Amazon’s Lambda), however, are proprietary: when you write to the API for Lambda or Google’s Cloud Functions, you’re locked into that vendor.
There’s currently no (well, there’s OpenWhisk) generic way to do the auto-scale function thing on a private cloud or in a way that can migrate from one cloud provider to another.
Funcatron addresses this. Funcatron is a cloud-provider-neutral mechanism for developing, testing, and deploying auto-scalable functions.
Funcatron is designed to run on container orchestration clusters: Mesos, Kubernetes, or Docker Swarm.
Software Lifecycle
Software goes through a lifecycle:
-
Authoring
-
Testing
-
Staging
-
Production
-
Debugging
Funcatron addresses software at each stage of the lifecycle.
Authoring
An engineers sits down to write software. The faster the turn-around between code written and “trying it out,” the more productive the engineer will be.
Funcatron supports a “save, reload” model where the engineer saves a file (presuming they’re using an IDE that does compilation on save or are using a non-compiled language), and their function endpoints are available. That’s it. No uploading. No reconfiguration. No waiting. The endpoint is available on save.
Further, the Funcatron model requires knowledge of two things:
-
Swagger
-
How to write a simple function in Java, Scala, Clojure, Python, or JavaScript.
That’s it.
The engineer defines the endpoints in Swagger and uses the operationId to specify the function (or class for Java and Scala) to apply when then endpoint is requested. Funcatron takes care of the rest.
Between the fast turn-around and low “new stuff to learn” quotient, it’s easy to get started with Funcatron. It’s also easy to stay productive with Funcatron.
Also, developers need only have Docker installed on their development machine to live-test Funcatron code.
Testing
Because Funcatron endpoints are single functions (or methods on newly instantiated classes), writing unit tests is simple. Write a unit test and test the function.
Staging
Funcatron code bundles (Funcs) contain a Swagger endpoint definition and the functions that are associated with the endpoint and any library code. For JVM languages, these are bundled into an Uber JAR. For Python, a PEX file. The Swagger definitions for an endpoint are unique based on host name and root path.
Funcatron supports aliasing Swagger fields and values in different environments such that a single Swagger definition can be run in staging and testing environments without change. Thus, there’s one deployment unit (a Func bundle) that have well defined behaviors across test, staging, and production servers.
Production
Funcatron allows simple deployment and undeployment of end-point collections defined in Swagger files and implemented in a JVM language, Python, or NodeJS.
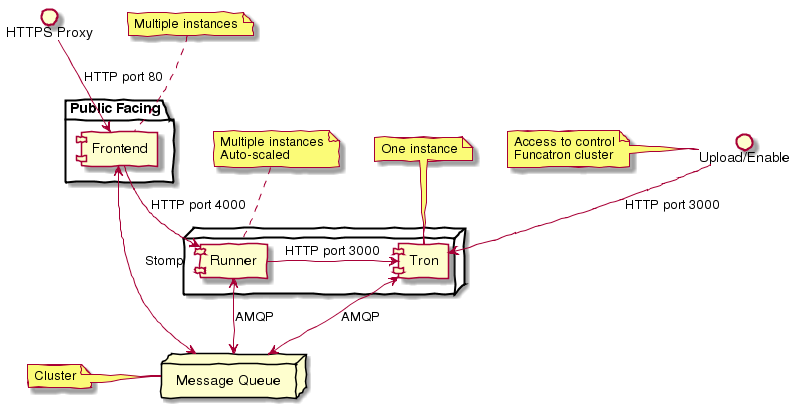
Requests are forwarded from Nginx via a message queue to a dispatcher (a Tron). Based on the hostname and root path, the message is placed on a queue for a specific Func. The Func processes the request and sends the response to a reply queue. The Nginx process dequeues the response and returns it as an HTTP response.
The number of Func instances running on a cluster is based on the queue depth and response time. The Func manager sends statistics back to the Trons and the Trons change Func allocation based on these statistics by communicating with the container orchestration substrate (Mesos, Kubernetes, Swarm) and changing the allocation of Func running containers.
From the DevOps point of view: deploy a Func and it binds to the appropriate HTTP endpoint and scales to handle load.
Debugging & Test Cases
Funcatron logs a unique request ID and the SHA of the Func with every log line related to a request. This allows correlation of requests as they fan out through a cluster.
Funcatron allows dynamic changing log levels on a Func-by-Func basis which allows capturing more information on demand.
All communications between the front end, Funcs, and back again are via well defined JSON payloads. Funcatron allows capturing request and response payloads on a Func-by-Func basis (complete streams, or random sampling). This data can be used for testing or debugging.
Architecture
Funcatron has some ambitious goals… and has an architecture to facilitate achieving these goals.
In all but development mode, Funcatron runs on a Docker container orchestration system: Mesos, Kubernetes, or Docker Swarm. We call this the "container substrate." Each of the Funcatron components can be scaled independently with messages to the container substrate.
For HTTP requests, Funcatron uses Nginx and Lua (via the OpenResty project) to handle the HTTP requests. A small Lua script encodes the request as a payload that’s sent to a message broker (initially RabbitMQ, but this will be pluggable, e.g. Kafka, Redis). For large request or response bodies, there will be a direct connection between the Front End and the Runner. For all but the highest volume installations, 2 Nginx instances should be sufficient.
Based on the combination of host and pathPrefix attributes in the Swagger module definition, the Tron enqueues the request on the appropriate queue.
A Runner module dequeues messages from a number of host/pathPrefix queues and forwards the request to the appropriate Func. The runner then takes the function return value and appropriately encodes it and places it on the reply queue which dequeued by the original endpoint.
Each Func can run multiple modules. Based on queue depth, queue service time, and CPU usage stats from the Funcs, more runners can be allocated on the substrate, or more Funcs can be allocated across the runners.
The Lua scripts dequeues the response and turns in into an Nginx response.
Because all of the operation of the Funcs and Trons can be captured as messages (and all the messages are in JSON), it’s possible to capture message streams for testing and debugging purposes.
Every request has a unique ID and each log line includes the unique ID so it’s possible to correlate a request as it moves across the cluster.
Notes
The initial implementation uses Nginx/OpenResty, RabbitMQ, Java/Scala, and Mesos to support HTTP requests. This is not “hardcoded” but pluggable. Specifically:
-
Anything that can enqueue a payload and dequeue the response can work with the rest of Funcatron. The initial implementation is HTTP via Nginx/OpenResty, but nothing in the rest of the system depends on what enqueues the request and dequeues the response.
-
RabbitMQ is the initial message broker, but it could be Kafka, Redis, or any other message broker. This is pluggable.
-
Initially, dispatch from Runners to Funcs will be Java/Scala/Kotlin classes. But the dispatch is also pluggable so other languages (Clojure) and runtimes (Python, NodeJS, Ruby/Rails) will be supported.
-
“But Swagger is HTTP only” well… yes and no… the verb and the scheme are HTTP-specific, but they can be ignored… and by the time the request is dequeued by the Runner, the origin (HTTP or something else) of the message is irrelevant. The power of Swagger is two-fold:
-
Excellent definitions of incoming and outgoing data shapes
-
Great tooling and lots of general Swagger skills
-
Because everything in Funcatron is asynchronous messages, how the messages are passed, where the message originate and where responses are dequeued are all pluggable and irrelevant to the other parts of the system.
The key idea in Funcatron is the Func is a well defined bundle of functionality that’s associated with a particular message signature that maps to well HTTP via host, pathPrefix, path, and verb, but could map to something else.
It may be possible to chain Func invocations. I don’t yet have a concrete design, but rather than enqueuing a Func return value as a response, it may be possible to package it as a request (the request body contains the Func return value) and forwarding it to another Func for further processing.
Finally, if there’s no reply-to field in a message, the Func is applied (invoked) but the results are discarded. This allows for side effects from the Func rather than just computation.
Contributing
Please see CONTRIBUTING for details on how to make a contribution.
Licenses and Support
Funcatron is licensed under an Apache 2 license.
Support is available from the project’s founder, [David Pollak](mailto:[email protected]).
Documentation Versions
-
master
-
v0.2.6